Most of the time, you’ll start creating a workflow with a single data source (or set of sources) in mind. Therefore, you build your references, your row selections, your filters, etc. based on whichever data example you have on hand at that time. This will work great for that dataset and you’ll always be able to modify your workflow to fit a new dataset with different structures, but sometimes you’ll want to create a workflow that doesn’t need to be modified – a workflow that’s flexible enough to work with disparate data sources. There are tradeoffs here; as you decrease the required specificity of your input, you risk reducing accuracy and increase development time. Familiarity with the techniques and concepts I’ll introduce here for improving workflow flexibility will help you know when to employ them and when to hardcode your configuration.
The Dynamic/Unknown Field Checkbox
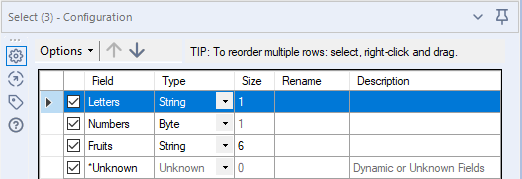
The Unknown field feature of Join, Transpose, and Select tools is frequently overlooked and critical to the process of creating both static and flexible workflows. Leaving the Unknown field checked will allow any fields that are not currently accounted for by the Select tool to pass to the other side. Unchecking Unknown field will only allow the currently selected fields to pass, thereby excluding any new fields that are not manually selected.
Example: My workflow source is a database table that was recently updated to contain two additional columns. I have a workflow that pulls from the database and sends the results as an email every morning with minimal modification. If Unknown field is selected in all my field selections, those two new columns will be in the final output. If not, the emails will only contain the columns that were present at the time the workflow was created.
If your dataset is subject to change, deselecting Unknown fields will ensure your existing logic will continue to function. Modifying a workflow to function properly with new, unknown fields can necessitate additional tools.
Dynamic Input, Rename, Replace, and Select

Located in the Developer set of tools, the dynamic tools are modified versions of basic tools designed to operate based on conditionals or additional inputs.
Dynamic Input: With a normal Input Data tool, data are read from the source specified in the tool configuration. The Dynamic Input tool accepts lists of the following to modify a sample source reference:
- Full File Paths
- File Names
- Prefixes/Suffixes for File Names
- Values for modifying SQL Queries
With these modifications, the Dynamic Input tool can bring in data from several sources if each file or table being referenced has the same field schema (Field Names, Types, and Sizes). If files are similar but not the same, they can be standardized as part of a batch macro.
Dynamic Rename: Normally, fields are renamed manually with a Select tool field by field. Dynamic Rename uses formulas or other data streams to rename the fields in a dataset.
Example: Remove a prefix from some or all fields, replace field headers with the first row of data, or use a second file as the field name source.
Dynamic Replace: Like a standard Find Replace tool, Dynamic Replace identifies and replaces specific values in a data column. Rather than relying on a static list of values to match and replace, the Dynamic Rename relies on either a list of Boolean operators with associated replacements or replacement options that incorporate fields and calculations.
Example: Add additional Find/Replace options without needing the exact matching field to allow for unexpected values.
Dynamic Select: Like the rest of the Dynamic tools, Dynamic Select switches a standard tool product from manual selections/entries to a formula or condition. Fields can be selected/deselected based on conditional logic or the field type.
Example: If a process needs to be applied only to an indeterminate number of numeric fields, create a record ID, dynamically select numeric fields and perform an operation on all columns, then join back on record ID.
Transpose and Crosstab

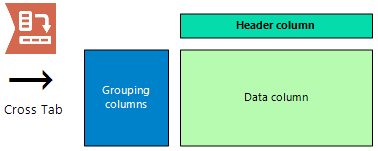
The Transpose and Crosstab tools are frequently used together to modify and reshape fields. There are many ways that these tools can be used to improve the flexibility of workflow, one of which is highlighted here.
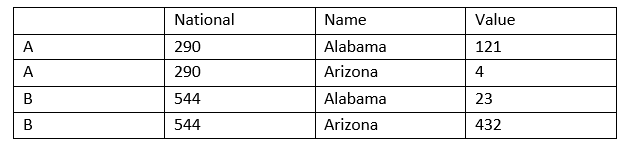
Indeterminate Number of Columns for Calculations

Example: To calculate a row level breakdown of Sales % per state, each state would need hard-coded references (Alabama %= Alabama/National). With Transpose and Crosstab tools, the reference can be switched to Value/National and any new state columns would automatically be accounted for.
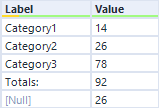
Multi-Row Formula
The Multi-Row Formula tool is useful in dynamic workflows because it allows a workflow to identify data based on bounding conditions. The multi-row formula can create a field that toggles its value once a certain value is identified, either in a row or a transposed column, and that toggle can be used as a filtering criterion to limit a database.
Example: To exclude a total row and all subsequent rows from a dataset, a self-referential multi-row formula that preserves the previous value unless the Total line label is identified will create the field on which to filter.

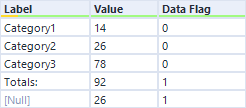
Utilizing some or all of these techniques can make the difference between a workflow that saves time over the course of the month but gets rebuilt for the new month’s dataset and a workflow that is built once and only needs modification every two years. Look first for opportunities to build dynamic workflows anywhere you find datasets that vary slightly from period to period and work up to creating new tools and macros that can be used in any number of processes. For additional practice, explore the Alteryx weekly challenges (https://community.alteryx.com/t5/Weekly-Challenge/bd-p/weeklychallenge).
For more information, please contact sales@capitalizeconsulting.com.